|
ClickHouse是俄罗斯的搜索巨头Yandex公司开发的面向列式存储的关系型数据库(DBMS), 于2016年开源,使用C++编写的,主要用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告。 ClickHouse 是过去两年中 OLAP 领域中最热门的。 ClickHouse的初始设计目的是为了服务于自己公司的一款名叫Yandex.Metrica的产品。 Metrica是一款Web流量分析工具,基于前方探针采集行为数据,然后进行一系列的数据分析, 类似数据仓库的OLAP分析。而在采集数据的过程中,一次页面click(点击),会产生一个event(事件)。 所以,整个系统的逻辑就是基于页面的点击事件流,面向数据仓库进行OLAP分析。 所以ClickHouse的全称是Click Stream(点击流),Data WareHouse(数据仓库),简称ClickHouse。 ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。 在传统的行式数据库系统中,数据按如下顺序存储:
处于同一行中的数据总是被物理的存储在一起。 常见的行式数据库系统有: 在列式数据库系统中,数据按如下的顺序存储:
这些示例只显示了数据的排列顺序。来自不同列的值被单独存储,来自同一列的数据被存储在一起。 OLAP场景的关键特征
输入/输出
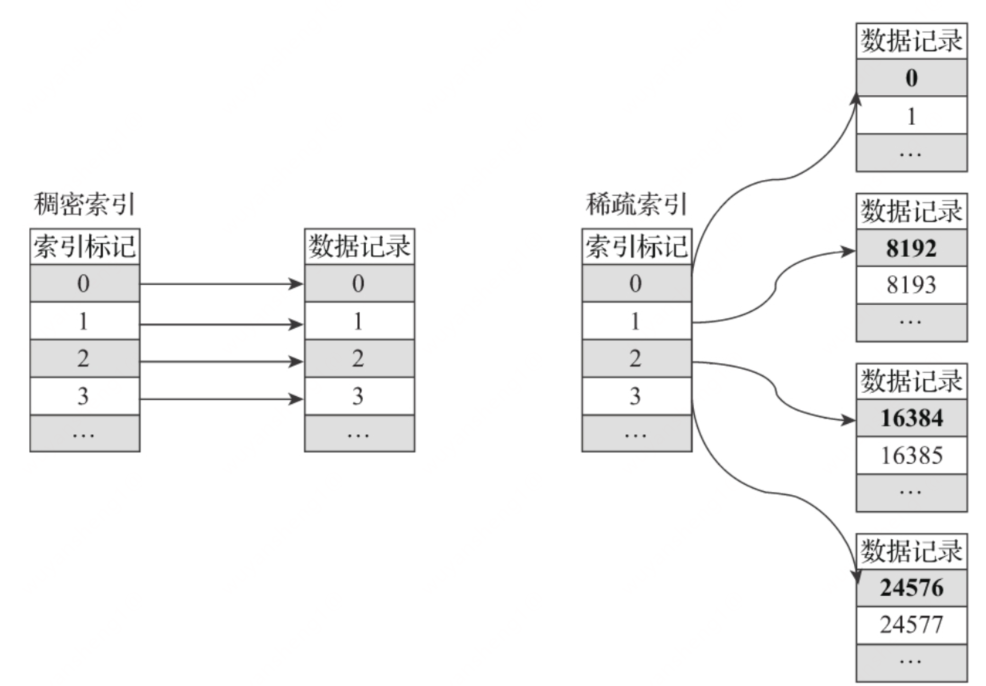
CPU由于执行一个查询需要处理大量的行,因此在整个向量上执行所有操作将比在每一行上执行所有操作更加高效。同时这将有助于实现一个几乎没有调用成本的查询引擎。如果你不这样做,使用任何一个机械硬盘,查询引擎都不可避免的停止CPU进行等待。所以,在数据按列存储并且按列执行是很有意义的。 数据压缩在一些列式数据库管理系统中(例如:InfiniDB CE 和 MonetDB) 并没有使用数据压缩。但是, 若想达到比较优异的性能,数据压缩确实起到了至关重要的作用。 除了在磁盘空间和CPU消耗之间进行不同权衡的高效通用压缩编解码器之外,ClickHouse还提供针对特定类型数据的专用编解码器,这使得ClickHouse能够与更小的数据库(如时间序列数据库)竞争并超越它们。 多服务器分布式处理上面提到的列式数据库管理系统中,几乎没有一个支持分布式的查询处理。 在ClickHouse中,数据可以保存在不同的shard上,每一个shard都由一组用于容错的replica组成,查询可以并行地在所有shard上进行处理。这些对用户来说是透明的 向量引擎为了高效的使用CPU,数据不仅仅按列存储,同时还按向量(列的一部分)进行处理,这样可以更加高效地使用CPU。 索引按照主键对数据进行排序,这将帮助ClickHouse在几十毫秒以内完成对数据特定值或范围的查找。 稠密索引:一条数据创建一条索引 稀疏索引:一段数据创建一条索引
一级索引是稀疏索引,意思就是说:每一段数据生成一条索引记录,而不是每一条数据都生成索引, 如果是每一条数据都生成索引,则是稠密索引。用一个形象的例子来说明:如果把MergeTree比作一本书, 那么稀疏索引就好比是这本书的一级章节目录。一级章节目录不会具体对应到每个字的位置, 只会记录每个章节的起始页码。 MergeTree 的主键使用 PRIMARY KEY 定义,待主键定义之后,MergeTree 会依据 index_granularity 间隔 (默认 8192 行),为数据表生成一级索引并保存至 primary.idx 文件内。 支持数据复制和数据完整性 ClickHouse使用异步的多主复制技术。当数据被写入任何一个可用副本后,系统会在后台将数据分发给其他副本,以保证系统在不同副本上保持相同的数据。在大多数情况下ClickHouse能在故障后自动恢复,在一些少数的复杂情况下需要手动恢复。 限制
单个大查询的吞吐量吞吐量可以使用每秒处理的行数或每秒处理的字节数来衡量。如果数据被放置在page cache中,则一个不太复杂的查询在单个服务器上大约能够以2-10GB/s(未压缩)的速度进行处理(对于简单的查询,速度可以达到30GB/s)。如果数据没有在page cache中的话,那么速度将取决于你的磁盘系统和数据的压缩率。例如,如果一个磁盘允许以400MB/s的速度读取数据,并且数据压缩率是3,则数据的处理速度为1.2GB/s。这意味着,如果你是在提取一个10字节的列,那么它的处理速度大约是1-2亿行每秒。 处理短查询的延迟时间如果一个查询使用主键并且没有太多行(几十万)进行处理,并且没有查询太多的列,那么在数据被page cache缓存的情况下,它的延迟应该小于50毫秒(在最佳的情况下应该小于10毫秒)。 否则,延迟取决于数据的查找次数。如果你当前使用的是HDD,在数据没有加载的情况下,查询所需要的延迟可以通过以下公式计算得知: 查找时间(10 ms) * 查询的列的数量 * 查询的数据块的数量。 处理大量短查询的吞吐量在相同的情况下,ClickHouse可以在单个服务器上每秒处理数百个查询(在最佳的情况下最多可以处理数千个)。但是由于这不适用于分析型场景。因此我们建议每秒最多查询100次。 为什么是100,不支持高并发? ClickHouse快是因为采用了并行处理机制,即使一个查询,也会用服务器一半的CPU去执行,所以ClickHouse不能支持高并发的使用场景,默认单查询使用CPU核数为服务器核数的一半,安装时会自动识别服务器核数,可以通过配置文件修改该参数。 为什么要使用一半的CPU呢? clickhouse每次数据写入都会生成一个新的分区版本,clickhouse异步合并分区数据,时间官网说是10分钟-15分钟。 在clickhouse中数据被分成了多个分区,查询某条数据时通过多分区的数据,利用CPU的多核同时并行处理获取数据,降低了查询时长; 数据的写入性能我们建议每次写入不少于1000行的批量写入,或每秒不超过一个写入请求。当使用tab-separated格式将一份数据写入到MergeTree表中时,写入速度大约为50到200MB/s。如果您写入的数据每行为1Kb,那么写入的速度为50,000到200,000行每秒。如果您的行更小,那么写入速度将更高。为了提高写入性能,您可以使用多个INSERT进行并行写入,这将带来线性的性能提升。 为什么写入性能这么好? ClickHouse中的MergeTree也是类LSM树的思想,日志结构合并树,但不是树,而是利用磁盘顺序读写能力, 实现一个多层读写的存储结构 是一种分层,有序,面向磁盘的数据结构,核心思想是利用了磁盘批量的顺序写要远比 随机写性能高出很多 大大提升了数据的写入能力。 充分利用了磁盘顺序写的特性,实现高吞吐写能力,数据写入后定期在后台Compaction。 在数据导入时全部是顺序append写,在后台合并时也是多个段merge sort后顺序写回磁盘。 聚合与非聚合数据有一种流行的观点认为,想要有效的计算统计数据,必须要聚合数据,因为聚合将降低数据量。 但是数据聚合是一个有诸多限制的解决方案,例如:
如果我们直接使用非聚合数据而不进行任何聚合时,我们的计算量可能是减少的。 为什么查询这么快利用存储引擎的特殊设计充分减少磁盘I/O对查询速度的影响。从用户提交一条SQL语句进行查询到最终输出结果的过程中,大量的时间是消耗在了磁盘I/O上,在很多情况下,I/O所占用的时间可以达到整个时间的90%以上。对存储引擎磁盘I/O的优化可以获得非常大的收益。ClickHouse的存储引擎设计中大量优化的目的也是为了减少磁盘I/O。 参考文档: https://www.toutiao.com/article/7256596641862566463/?channel=&source=search_tab |